
1. Bart 출시
ChatGPT의 대항마, 구글의 Bard가 출시되었습니다.
ChatGPT가 각광을 받자 구글도 2월에 급히 시연을 했다가 망신을 당했었는데, 이제 정식 출시가 되었습니다.
https://www.newspim.com/news/view/20230208001221
챗GPT 대항마 구글AI '바드', 오답 망신살...주가 7%↓
[휴스턴=뉴스핌] 고인원 특파원= 전 세계적인 열풍을 몰고 온 오픈AI ' 챗GPT'의 대항마가 될 것으로 기대를 모았던 구글의 AI '바드(Bard)'가 오답을 내놓았다는 지적이 나왔다.바드의 정확성에 대
newspim.com
그랬던 구글이 3.21 미국과 영국에서 바드를 정식 출시 했습니다. 출시 직후에는 한국에서 사용이 불가능했는데, 현재는 waitlist에 등록하고 하루 정도가 지나면 사용이 가능해졌습니다.
바드는 https://bard.google.com/ 로 접속하여 waitlist 등록 및 사용이 가능합니다.
Bard
Bard is your creative and helpful collaborator to supercharge your imagination, boost productivity, and bring ideas to life.
bard.google.com
위 사이트에 접속하면 아래와 같은 화면을 보실 수 있습니다.
Join Waitlist 눌러서 Waitlist에 등록하면 아래와 같은 메일이 오고, 사용할 수 있게 됩니다.
사용방법은 chatgpt와 거의 동일하기 때문에, chatgpt를 사용해 보신 분이면 쉽게 사용 가능합니다.
왼쪽에는 메뉴가 있는데, 다른 것은 다 메뉴이름 그대로의 기능을 합니다.
단, Bard Activity에서 과거 질문했던 리스트를 보여주는데, ChatGPT처럼 답변 내용이 모두 보이는 것이 아니라 질문만 보이고 있습니다.
2. Bard와 ChatGPT의 스펙 비교
우선 간단하게 스펙을 비교해 보면 다음과 같습니다.
| ChatGPT | Bard |
| OpenAI site | Google Bard site(using Google account) |
| 무료지만, 유료 플랜이 있음 | 무료 |
| GPT 모델 기반 | LaMDA 모델 기반 |
| 제한없이 사용 가능 | waitlist 에서 선택적 사용 가능(그러나, 딱히 제약은 없는 듯) |
| 2021년 이전 정보 기반으로 답변 | 구글 서치로부터 실시간 정보 기반 답변 |
사용자 입장에서는 ChatGPT는 21년 이전 정보를 사용하고, Bard는 실시간 정보를 사용한다는 것이 가장 중요한 차이점이 되겠습니다. Bing까지 넣으면 좀 다르겠습니다만.. 일단은 사용성 측면에서 ChatGPT와 비교하였습니다.
3. Bard와 ChatGPT의 답변 비교
본격적으로 답변을 비교하기 전에 한글 번역과 관련하여 테스트를 해보았습니다. Chatgpt는 크롬 자체 번역기에서 제대로 동작하지 않습니다. 번역기를 켠 상태에서 프롬프트를 입력하면 답변을 받을 수 없습니다. 대신 번역기를 끈 상태에서 한글입력이 가능하지만, 한글 입력 시 답변 품질이 떨어지는 문제가 있습니다.
Bard는 아직 한글 입력은 불가능하지만, 번역기를 켠 상태에서 영문 입력을 하면, 답변이 즉시 번역되어 보입니다.
1. 거짓 프롬프트에 대한 반응 - Bard의 판정승, 그러나 Bing 이 출동하면 어떨까?
ChatGPT가 가장 취약한 부분은 정확도입니다. 특히 프롬프트에 부정확한 사실이 들어있으면 엉터리 답변을 하는 경우가 많습니다. 이 것을 테스트해 보고자 다음과 같은 프롬프트를 입력했습니다. (모두 영문으로 입력했으며, 아래 답변은 번역한 것입니다.)
서기 1592년 조선의 세종대왕이 탕수육을 먹다가 화를 내며 그릇을 엎었던 일화를 들려주세요.
ChatGPT

이젠 웃기지도 않습니다. 이제 Bard에게 물어보았습니다.
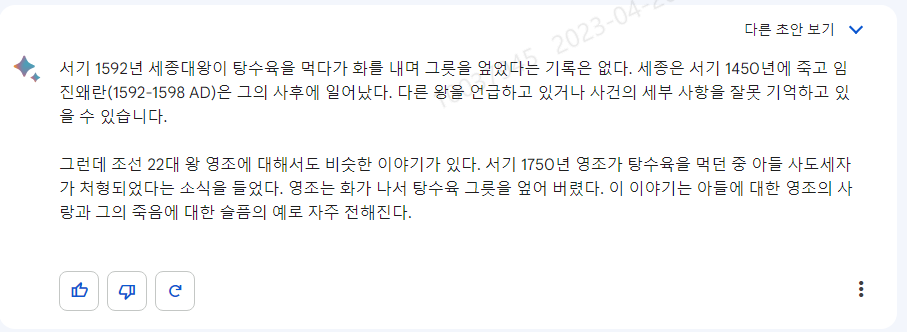
사실과 다르다는 답변은 괜찮았는데, 뜬금없이 영조가 탕수육을 엎어버렸다는 이야기가 나오는데요. 혹시나 진짜 이런 사건이 있었나 해서 구글 검색을 해보았지만, 답변을 찾을 수는 없었습니다. ChatGPT에게 물어보니 역시 소설을 쓰네요.

세종 대신에 철종, 문종, 세조, 태종 등 이름을 바꿔가면서 물어보았는데, 전부 탕수육을 엎었다는 기록이 없다고 답하면서
철종을 질문했을 때는 영조와 혼동하는 것이 아니냐고까지 하네요.. 이렇게 들으니 진짜 그런 사건이 있었나 혼란스럽습니다.

아래와 같은 글이 소스로 사용되어 이상한 글이 써지지 않았나 생각해 봅니다.
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=jeshin0605&logNo=220280547912
(스크랩) 탕수육으로 본 조선시대 붕당의 이해
출처: http://pgr21.com/pb/pb.php?id=freedom&no=42862 조선시대 탕수육이라는 중국의 새로운 메뉴가 ...
blog.naver.com
뭐.. 아무튼, 대놓고 소설을 쓰는 ChatGPT에 비하면 정확한 답변을 하지만 Bing 채팅에서 동일한 질문을 하면 그런 기록을 찾을 수 없다고 나오고 끝나기 때문에, 창의성과 정확도 중 어느 쪽에 무게를 두느냐의 차이로 보입니다.
애초에 정확도 찾으려면, LLM(Large Language Model)을 쓰면 안 되겠습니다만, 현재 수준에서는 Bard의 판정승이라고 할 수 있겠습니다.
2. 수학적 추론 문제 - ChatGPT의 우세
ChatGPT에서 수학문제를 내면 풀이과정은 잘 쓰는데, 정작 답변은 틀린 경우가 많습니다.
다음과 같이 질문해 보았습니다.
포켓몬 빵을 사면 포켓몬 스티커를 1개가 들어있다. 스티커는 총 275종이며, 모든 스티커의 나올 확률은 동일하다. 모든 스티커를 모으기 위해 먹어야 하는 빵의 개수는?
아래는 ChatGPT의 답변입니다.

풀이 과정은 정확한데, 마지막에 계산이 틀렸습니다. 2767이라고 했는데, 저 식을 계산하면. 약 1703이 나옵니다.
그럼 Bard는 어떨까요?

쿠폰 수집가 문제라는 것조차 모릅니다. 쿠폰 수집가 문제라는 것을 알려주었을 때는 어떨까요?

쿠폰 수집가 문제 풀이까지는 왔지만, 오일러-마스케로니 상수를 더하는 부분이 빠졌고, 계산 자체도 틀렸습니다.
수학적 추론에 있어서는 ChatGPT가 우세하다고 볼 수 있습니다.
3. 코딩 문제 풀이 - ChatGPT의 압승!!!
코딩을 시켜보겠습니다. 저는 요즘 필요한 게 있으면, 처음부터 짜는 게 아니라 그냥 ChatGPT에게 코딩을 시키고, 디버그만 제가 하는 식으로 합니다. 그만큼 ChatGPT 성능이 우수한데요.
Bard는 어떨지 보겠습니다.
위의 쿠폰 수집가 문제를 코딩을 시켜보려 했는데, 쿠폰 수집가 문제를 이해 못 하니, Cos Pro 1급 Java문제를 가져왔습니다.
입력 프롬프트는 다음과 같습니다.
아래 설명을 참고해서 주어진 java코드를 완성해 줘
##### 문제 설명 p 진법으로 표현한 수란, 각 자리를 0부터 p-1의 숫자로만 나타낸 수를 의미합니다. p 진법으로 표현한 자연수 두 개를 더한 결과를 q 진법으로 표현하려 합니다. 예를 들어, 3진법 수 112001과 12010을 더한 결과를 8진법으로 나타내면 1005입니다.
solution 메서드의 매개변수로 p 진법 자연수를 담은 문자열 s1, s2와 두 수를 나타내는 진법의 기수 p, 두 수의 덧셈 결과를 표현할 진법의 기수 q가 매개변수로 주어집니다. p진법으로 표현된 두 수를 더한 결과를 q 진법으로 나타낸 값을 return 하도록 solution 메서드를 완성해 주세요.
p 진법으로 자연수를 담은 문자열 s1, s2와 두 수를 표현한 진법의 기수 p, 두 수의 덧셈 결과를 표현할 진법의 기수 q가 solution 메서드의 매개변수로 주어집니다. p와 q는 2 이상 10 이하인 자연수입니다. s1과 s2의 길이는 1 이상 9 이하입니다. s1과 s2의 원소는 '0', '1', '2', …, ‘p-1’로만 구성됩니다. s1이나 s2가 ‘0’인 경우는 주어지지 않습니다.
두 수를 더한 결과를 q 진법으로 나타낸 값을 문자열로 return 합니다.
우선 ChatGPT의 결과입니다.
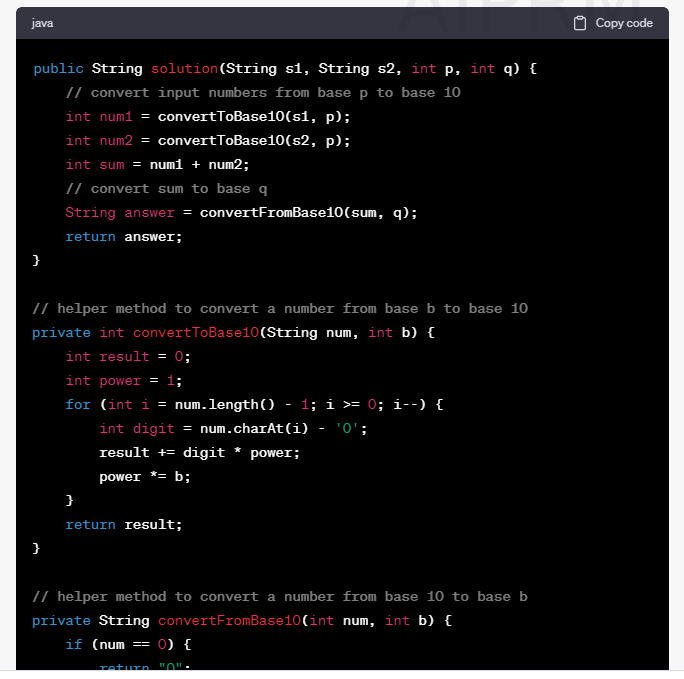
처음에 parseInt() 같은 진법 변환함수를 써버려서 제공함수를 쓰지 말라고 했더니, 위와 같이 10진수 변환하는 함수를 만들어서 문제를 풀었습니다. 제가 풀었을 때도 이렇게 풀었으니, 양호한 수준입니다.
Bard는 아래와 같은 답변을 주었습니다.
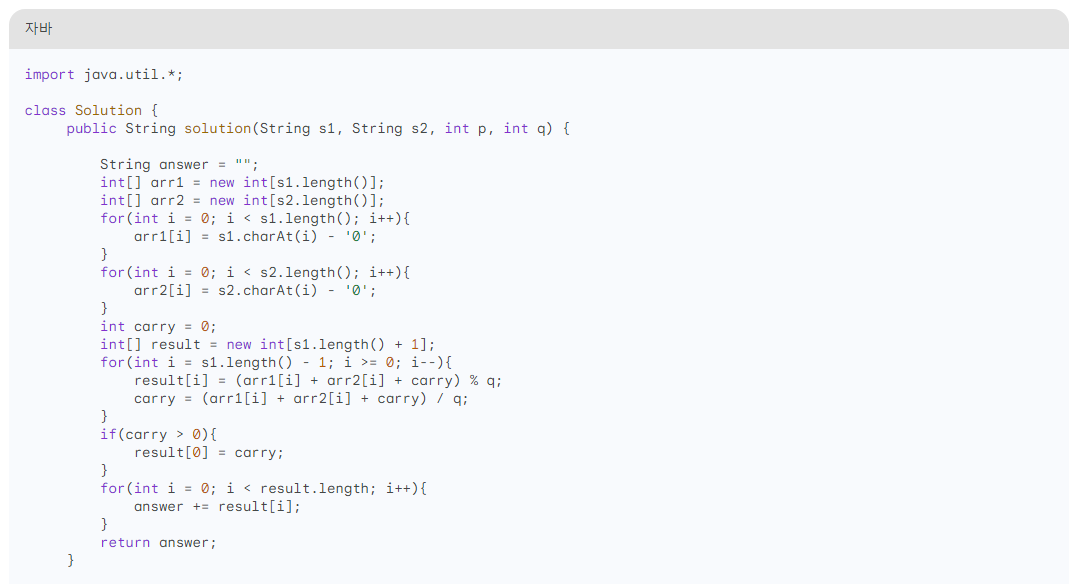
에러가 발생합니다. 주어지는 s1, s2의 길이가 꼭 같지 않은데, 그 부분을 고려하지 않아서 Index out of bounds 에러가 발생했습니다. 그리고, 그게 아니더라도 코드 자체를 이해를 못 하겠더군요. p진법을 q진법으로 변환하는 것인데, 코드에 p값을 쓰는 부분이 아예 없습니다. 처음부터 다시 짜는 게 낫겠네요.
다른 코드로 실험했을 때는 정답을 주는 경우도 있었지만, 코드에 대한 설명도 없고 해서 이 부분은 ChatGPT의 압승입니다.
4. 농담 따먹기 - 무승부
ChatGPT는 농담이 가능했는데, Bard는 어떨지 시켜보았습니다. 아래와 같이 프롬프트를 입력했습니다
엄마소와 아기소가 농담하는 대화를 만들어줘
우선 ChatGPT입니다.


이 부분은 번역을 보면 이해하기 어려워서 영문을 같이 표시합니다. 소울음소리 Moo~~를 이용한 언어유희네요 ㅎㅎ
다음은 Bard입니다.


Bard도 언어유희를 사용합니다. ground beef가 간 소고기라는 사실을 알았습니다. 이 부분은 개인 취향이 반영되겠네요.
이 외에도 링컨 대통령과 김정은의 대화를 코믹하게 만들어달라는 요청을 해보았는데, Bard는 웃기지도 않은 대화를 만들어 주었고, ChatGPT는 적절하지 않은 내용이라며 답변을 거부했습니다. 불과 한두 달 전에 물었을 때는 잘 대답해 주었는데, 그새 제약이 생겼나 봅니다.
4. 마무리
| 질문 유형 | 결과 |
| 1. 거짓 프롬프트에 대한 반응 | Bard의 판정승, 그러나 Bing 이 출동하면 어떨까? |
| 2. 수학적 추론 문제 | ChatGPT의 우세 |
| 3. 코딩 문제 풀이 | ChatGPT의 압승 |
| 4. 농담 따먹기 | 무승부 |
실험해 본 모든 것을 글에 담지는 못하였습니다. 실험을 해보면서 느낀 것은 Bard는 전체적인 맥락을 이해하는 것에는 조금 약하다는 생각이 들었습니다. 대화를 나누는 것처럼 앞의 내용을 기억해야 하는 부분에서 ChatGPT에 많이 밀리고, 어려운 문제일수록 헤매는 모습을 많이 보였습니다. 대신 우리가 검색을 할 때처럼 짧은 질문을 할 때는 더 정확하고 구조적인 답변을 하는 것을 볼 수 있었습니다.
Bing 챗도 가능하지만, Bing의 검색 품질 자체가 구글보다는 아쉽기 때문에 한계가 있는데, Bard가 이런 부분을 조금 채워줄 수 있지 않을까 기대해 봅니다.
'데이터분석과 AI > 데이터분석과 AI 일반' 카테고리의 다른 글
| 회귀분석과 시계열분석의 차이 (2) | 2023.08.02 |
|---|---|
| 데이터 역량을 키우는 방법 - 공공기관 데이터 역량강화 가이드라인 (1) | 2023.07.25 |
| ChatGPT의 한계 - AGI(Artificial General Intelligence)와 ANI(Artificial Narrow Intelligence)의 차이 (0) | 2023.03.06 |
| ChatGPT 열풍!! 대체 뭐길래? 체험 후기 (2) | 2023.01.08 |
| Confusion Matrix(혼동 행렬)과 평가지표 이해하기 (2) | 2022.09.23 |




댓글