
회사에서 시스템 개선을 위한 문제 발굴 차원에서 텍스트 데이터를 수집해서 분석을 하고 있습니다.
수십만 개 고객의견을 눈으로 보고 손으로 분류하기는 힘들어서 군집 분석을 한 후에 토픽 모델링으로 맥락을 찾으려고 했는데요.
대략적인 전처리를 한 후에 몇 가지 군집분석 알고리즘으로 분류를 해보았지만, 제대로 군집이 만들어지지는 않았습니다.
문득, 우리가 지도학습에서 앙상블 하는 것처럼 비지도학습에서도 앙상블을 할 수 있지 않을까 싶어서 ChatGPT의 도움을 받아 비지도학습 앙상블 하는 방법을 찾아서 공유합니다.
원래는 텍스트를 분류하는 것이었지만, 여기서는 간단하게 iris 데이터로 진행합니다.
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans, SpectralClustering, AgglomerativeClustering
from sklearn.metrics import adjusted_rand_score
import numpy as np
# iris dataset 로드
iris = load_iris()
X = iris.data
y = iris.target
# 군집분석 알고리즘 로드
kmeans = KMeans(n_clusters=3, random_state=42)
spectral = SpectralClustering(n_clusters=3, random_state=42, affinity='nearest_neighbors')
agglo = AgglomerativeClustering(n_clusters=3)
# 각 군집분석 알고리즘으로 학습 진행
kmeans_clusters = kmeans.fit_predict(X)
spectral_clusters = spectral.fit_predict(X)
agglo_clusters = agglo.fit_predict(X)우선 기본이 되는 모델들의 학습을 진행하고 군집을 만듭니다. 기본모델은 k-means, Spectral, Agglomerative 를 사용했습니다.
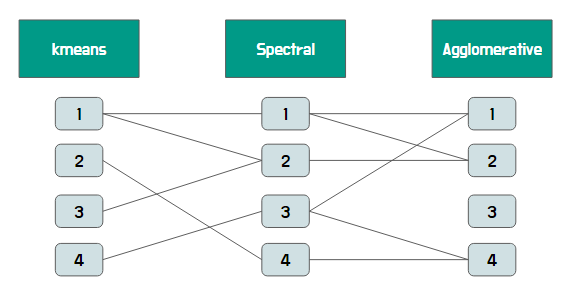
군집분석을 앙상블 해야겠다고 생각했을 때, 가장 어렵게 느낀 부분은 위의 그림처럼, 같은 label이 붙었다고 같은 군집이 아니라는 것입니다.
# 합의 행렬 계산
consensus_matrix = np.zeros((len(X), len(X))) #빈 행렬 생성
for i in range(len(X)):
for j in range(i, len(X)):
if i == j:
consensus_matrix[i,j] = 1
else:
consensus_matrix[i,j] = consensus_matrix[j,i] = \
(kmeans_clusters[i] == kmeans_clusters[j]) + \
(spectral_clusters[i] == spectral_clusters[j]) + \
(agglo_clusters[i] == agglo_clusters[j])그래서 비지도 학습의 앙상블에서는 위와 같이 데이터의 쌍을 만들고 이 쌍을 각 알고리즘이 같은 군집으로 묶는지를 봅니다. 예를 들어 전체 n개의 데이터가 있다면 nXn의 조합만큼 두 개의 쌍이 같은 군집으로 묶이는 지를 봅니다. 이를 위해 합의 행렬(Consensus Matrix)을 만드는데, 합의 행렬은 각 요소(i, j)가 데이터 포인트 i, j에 대한 각 알고리즘의 군집 간의 일치를 나타내는 정사각형 행렬입니다.
합의 행렬을 0으로 초기화한 다음 모든 데이터 포인트 쌍에 대해 중첩 루프를 사용하여 클러스터 할당 간의 합의를 계산합니다. 합의 행렬의 대각선 요소는 일치하는 위치이므로 1로 설정합니다. 이해를 돕기 위해 아래와 같이 그림을 추가합니다.

이제 위에서 만들어진 합의 행렬을 클러스터링 해서 앙상블 한 결과를 얻고, 기본 모델과 비교해 봅니다.
# Apply spectral clustering to consensus matrix
final_clusters = SpectralClustering(n_clusters=3, random_state=42, affinity='precomputed').fit_predict(consensus_matrix)
# Evaluate clustering performance
kmeans_ari = adjusted_rand_score(y, kmeans_clusters)
spectral_ari = adjusted_rand_score(y, spectral_clusters)
agglo_ari = adjusted_rand_score(y, agglo_clusters)
consensus_ari = adjusted_rand_score(y, final_clusters)
# Print adjusted rand index scores
print("Adjusted Rand Index for KMeans: {:.2f}".format(kmeans_ari))
print("Adjusted Rand Index for Spectral Clustering: {:.2f}".format(spectral_ari))
print("Adjusted Rand Index for Agglomerative Clustering: {:.2f}".format(agglo_ari))
print("Adjusted Rand Index for Consensus Clustering: {:.2f}".format(consensus_ari))
# Print comparison of performances
if consensus_ari > kmeans_ari and consensus_ari > spectral_ari and consensus_ari > agglo_ari:
print("Consensus Clustering performs the best.")
else:
best_algorithm = max((kmeans_ari, "KMeans"), (spectral_ari, "Spectral Clustering"), (agglo_ari, "Agglomerative Clustering"))[1]
print("{} performs the best.".format(best_algorithm))Output: 앙상블 결과 비교
Adjusted Rand Index for KMeans: 0.73
Adjusted Rand Index for Spectral Clustering: 0.76
Adjusted Rand Index for Agglomerative Clustering: 0.73
Adjusted Rand Index for Consensus Clustering: 0.75
Spectral Clustering performs the best.결과적으로 비지도학습의 앙상블은 기본모델의 평균정도의 결과를 얻었습니다. 얼핏 생각하기에, '그럼 가장 성능 좋은 클러스터링 방법을 쓰면 되는 거 아니야?'라고 생각할 수 있는데, 비지도학습에서 성능을 명확히 판단하기 어렵습니다. iris 데이터처럼 레이블이 있으면 정확도를 비교해볼 수는 있지만, 이상치에 의한 문제일 수도 있으므로 클러스터링 측면에서 꼭 더 낫다고 볼 수 있을지 모르겠네요.
그래서 실루엣 계수를 측정해 보았습니다.(실루엣 계수는 클러스터링이 얼마나 잘 되었는지를 나타냅니다.) 실루엣 계수로는 앙상블 모델이 가장 나은 결과를 보여주는 것을 볼 수 있습니다.
from sklearn.metrics import silhouette_score
# 기본 모델의 실루엣계수 계산
kmeans_silhouette = silhouette_score(X, kmeans_clusters)
spectral_silhouette = silhouette_score(X, spectral_clusters)
agglo_silhouette = silhouette_score(X, agglo_clusters)
# 앙상블 모델의 실루엣계수 계산
final_silhouette = silhouette_score(X, final_clusters)
# Print results
print("Silhouette Scores:")
print("K-means: ", kmeans_silhouette)
print("Spectral Clustering: ", spectral_silhouette)
print("Agglomerative Clustering: ", agglo_silhouette)
print("Consensus Clustering: ", final_silhouette)Output: 실루엣 계수
Silhouette Scores:
K-means: 0.5528190123564095
Spectral Clustering: 0.5541608580282851
Agglomerative Clustering: 0.5543236611296419
Consensus Clustering: 0.5553062646081594이렇게 비지도학습 모델을 앙상블하면 데이터의 특성에 좌우되지 않고, 평균적으로 높은 성능을 내는 모델을 만드는 데 유용하다고 볼 수 있겠습니다.
'데이터분석과 AI > 데이터분석과 AI 문법(Python)' 카테고리의 다른 글
| Inplace=True 옵션을 썼는데, 데이터 변경이 안되는 경우 (0) | 2023.06.11 |
|---|---|
| Label Encoidng 시 ValueError: y contains previously unseen labels:가 발생할 때 (0) | 2023.06.08 |
| Python에서 DataFrame의 목록을 출력하는 방법 (0) | 2022.09.13 |
| Python 함수 tooltip 보는 방법 (0) | 2022.09.06 |
| Jupyter Notebook, Jupyterlab 자동완성(TAB) 안될 때 (0) | 2022.08.23 |




댓글