728x90

파이썬에서 데이터를 로딩하고 가장 많이 사용하는 함수 중의 하나가 describe 함수입니다.
사용법은 간단한데, descirbe 함수가 범주형에 대해서도 통계정보를 생성해 준다는 것을 모르는 분들이 종종 있어서 정리해 놓습니다.
1. 예시 데이터 생성
import pandas as pd
data = {'Age': [25, 30, 22, 40, 28],
'Height': [170, 160, 175, 162, 180],
'Weight': [65, 70, 60, 75, 85],
'Gender': ['Male', 'Female', 'Male', 'Female', 'Male']}
df = pd.DataFrame(data)2. 수치형 데이터에 대한 통계 생성
print("Numeric Data Summary:")
df.describe()Output:

각 값에 대한 설명은 다음과 같습니다.
- count: 열에 있는 null이 아닌 값의 수입니다.
- mean: 열의 평균값입니다.
- std: 표준 편차입니다.
- min: 열의 최솟값입니다.
- 25%(25번째 백분위수): 1 사분위수라고도 하는 이 값은 데이터의 하위 25%를 구분하는 값입니다.
- 50%(50번째 백분위수 또는 중앙값): 데이터를 정렬할 때 중간 값입니다.
- 75%(75번째 백분위수): 3 사분위수라고도 하는 이 값은 데이터의 상위 25%를 구분하는 값입니다.
- max: 열의 최댓값입니다.
3. 범주형 데이터에 대한 통계 생성
범주형 데이터에 대해서는 아래와 같인 include='O'(대문자) 옵션을 주면 통계 출력이 가능합니다.
'O' 대신 'object'를 입력해도 동일한 결과를 얻을 수 있습니다.
print("\nCategorical Data Summary:")
df.describe(include='O')Output:
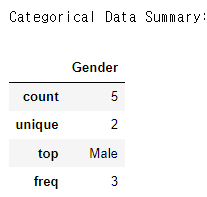
- count: 열에 있는 null이 아닌 값의 수입니다.
- unique: 열에 있는 고유한 고유 값의 수입니다.
- top: 열에서 가장 빈도가 높은 값입니다.
- freq: 가장 빈도가 높은 값의 빈도(개수)입니다.
4. 수치형과 범주형 한 번에 출력
수치형과 범주형 통계를 한 번에 출력하는 것도 가능합니다. include='all' 옵션을 주면 됩니다.
다만, NaN값이 출력되므로 그다지 예쁘지는 않습니다.
print("\nAll Data Summary:")
df.describe(include='all')Output:

728x90
'데이터분석과 AI > 데이터분석과 AI 문법(Python)' 카테고리의 다른 글
| 로그와 지수 함수 - np.log(), np.exp() (0) | 2023.07.15 |
|---|---|
| 동일한 플롯에 스케일이 다른 그래프를 그리고 싶을 때 twinx() (0) | 2023.07.13 |
| 수치형 데이터를 범주형으로 만드는 비닝(Binning)의 세 가지 방법 feat. Xverse (0) | 2023.07.06 |
| cross_val_score 할 때 scoring에 입력 가능한 파라미터 (0) | 2023.07.02 |
| 데이터분석 초보자가 자주하는 실수- 정확도, 정밀도, 재현율, F1-score 까지 모든 성능지표가 1인 경우 (0) | 2023.06.30 |




댓글