728x90

두 개의 독립적인 표본에 대해 정규성 가정이 충족되지 않으면 비모수 검정을 사용할 수 있습니다.
독립표본에 대한 비모수 검정 방법은 Mann-Whitney U 검정, Wilcoxon Rank Sum 검정이 있습니다.
이 두 가지 비모수 검정 방법은 두 독립 그룹의 중앙값을 비교하는 데 사용됩니다.
다음은 이에 대한 예제입니다.
※ 만약 데이터에 결측치가 존재하면 dropna()로 제거하고 진행합니다.
import numpy as np
# 정규성을 충족하지 않는 데이터 생성을 위해 지수분포를 사용
samp1 = np.random.exponential(scale=1, size=100)
samp2 = np.random.exponential(scale=1, size=100)
print(stats.shapiro(samp1)) #정규성을 충족하지 않는다.
print(stats.shapiro(samp2)) #정규성을 충족하지 않는다.Output: 두 표본 모두 p_value < 0.05 이므로 귀무가설이 기각되고, 정규성을 충족하지 않습니다.
ShapiroResult(statistic=0.8483412861824036, pvalue=1.0303372377507003e-08)
ShapiroResult(statistic=0.8297588229179382, pvalue=2.2696557966384034e-09)
이제 두 가지 방법으로 비모수 검정을 진행합니다.
#비모수 검정
print(stats.mannwhitneyu(samp1,samp2))
print(stats.ranksums(samp1,samp2))Output: 두 표본 모두 p_value > 0.05 이므로 귀무가설이 유지되고, 두 집단은 동질성을 갖고 있다고 볼 수 있습니다.
MannwhitneyuResult(statistic=5235.0, pvalue=0.5666618284390166)
RanksumsResult(statistic=0.5741963884746345, pvalue=0.5658349129654131)히스토 그램으로 분포를 확인해 봐도, 두 집단이 동질성이 있는 것으로 보입니다.
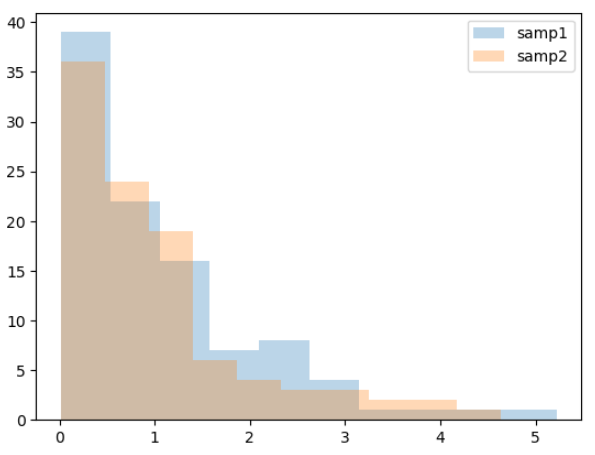
※ 위 내용은 "빅데이터 분석기사 실기 준비를 위한 캐글 놀이터" 및 "데이터마님 scipy tutorial"을 따라가며 공부한 내용입니다.
https://www.kaggle.com/datasets/agileteam/bigdatacertificationkr
Big Data Certification KR
빅데이터 분석기사 실기 (Python, R tutorial code)
www.kaggle.com
https://www.datamanim.com/dataset/97_scipy/scipy.html#t-one-sample
728x90
'데이터분석과 AI > 빅데이터 분석기사' 카테고리의 다른 글
| [빅데이터분석기사 실기][작업형1] 시간 데이터 다루기(datetime, timedelta) (0) | 2023.07.03 |
|---|---|
| [빅데이터분석기사 실기][작업형3] 검정 방법의 선택 (수치형 2집단, 3집단 및 범주형) (0) | 2023.06.27 |
| [빅데이터분석기사 실기][작업형3] 등분산 검정(levene, bartlett, fligner) (0) | 2023.06.25 |
| [빅데이터분석기사 실기][작업형3] 비모수 검정 wilcoxon 부호순위 테스트 (단일표본, 대응표본) (0) | 2023.06.24 |
| [빅데이터분석기사 실기] 시험 시 주의사항, 꿀팁 방출 (0) | 2023.06.23 |




댓글