
Confution Matrix란?
오늘 정리해 볼 것은 Confusion Matrix입니다.
시스템이 분류 문제를 얼마나 헷갈려하는지 알 수 있는 표라고 Confusion Matrix인데,
이 표를 보고 있는 사람도 혼동이 와서 혼동행렬이라는 우스갯소리가 있습니다.
분류 모델링의 성능을 나타내는 많은 평가 지표들이 Confusion Matrix에서 도출되기 때문에 중요합니다.
기본은 간단합니다
행방향으로는 예측에 대한 결과 열 방향으로는 실제 값을 표시하고, 경우에 따라 행/열이 바뀌는 경우도 있습니다.
| Actually Positive | Actually Negative | |
| Predicted Positive | True Positive(TP) | False Positive(FP) |
| Predicted Negative | False Negative(FN) | True Negative(TN) |
헷갈리지 않게 조금 더 부연 설명을 해보자면,
여기서 True는 실제와 예측이 일치한다는 뜻이고, False는 실제와 예측이 불일치한다는 뜻입니다.
Positive는 라벨(label)이 긍정인 것이고, Negative는 라벨값이 부정(label)인 것을 의미합니다.
우리는 Positive와 Negative를 얼마나 잘 맞추냐를 찾는 것이다. 라고 생각하고 있으면 덜 헷갈립니다.
당연한 것을 왜 말하느냐.. 지금은 당연한 것 같은데, Confusion Matrix를 공부하고 시간이 지나 생각해보면 헷갈립니다.
구글링 해서 나오는 Confusion Matrix에 대한 많은 포스팅에서 아래처럼 그리기도 합니다. 아래처럼 한다고 틀리느냐.. 하면 그것도 아니니까 더 문제입니다. 실제로 이진 분류문제에서 많은 경우에 라벨 값을 True/False라고 쓰기 때문이죠.
| Actually True | Actually False | |
| Predicted True | True Positive(TP) | False Positive(FP) |
| Predicted True | False Negative(FN) | True Negative(TN) |
몇 번 보다 보면 헷갈리는 거죠. FP가 긍정으로 예측한 것 중 긍정이 아닌 건지... 부정으로 예측한 것 중 부정이 아닌 것인지.. 이런 게 헷갈리게 됩니다.
그래서 다시 한번 정리하면, 우리는 Positive와 Negative를 예측하는 것이다. 라고 기억합시다.
| Actually Positive - 실제 긍정 | Actually Negative - 실제 부정 | |
| Predicted Positive - 예측 긍정 | True Positive(TP) - 진짜 긍정 | False Positive(FP) - 가짜 긍정 |
| Predicted Negative - 예측 부정 | False Negative(FN) - 가짜 부정 | True Negative(TN) - 진짜 부정 |
이제 Confusion Matrix에서 나오는 평가지표들을 살펴보겠습니다.
Accuracy(정확도)
모델이 얼마나 분류를 잘하는지를 나타내는 지표입니다. Confusion Matrix는 TP와 TN이 커야 예측이 잘 되는 모델입니다. True가 많아야 좋은 거죠. 100개의 샘플이 있다고 할 때 아래와 같이 TP와 TN의 합이 100이면 모두 맞춘 것이니 정확도 100%의 모델이 됩니다.
| Model | Actually Positive | Actually Negative |
| Predicted Positive | TP(50) | FP(0) |
| Predicted Negative | FN(0) | TN(50) |
이 것을 수식으로 표현하면 아래와 같이 됩니다.

즉, Accuracy는 전체 샘플 중에서 모델이 정답을 맞게 예측한 비율이라고 볼수 있습니다.
이제 예시를 들어서 볼까요?
카드사에서 카드대금 연체 가능성이 있는 고객과 카드대금을 정상 납부할 고객을 분류하는 모델을 만든다고 해보겠습니다. 만들어진 Model A는 아래와 같이 연체와 납부를 분류하였고, 이제 이것으로 정확도를 계산하겠습니다.
| Model A | Actually 연체 | Actually 납부 |
| Predicted 연체 | TP(3) | FP(5) |
| Predicted 납부 | FN(7) | TN(85) |
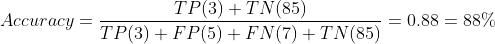
자, Model A는 정확도 88%의 아주 준수한 결과를 보여주었습니다.
그런데, 이게 카드사가 원하는 모델이 맞을까요?? 카드사는 연체고객을 예측해서 연체를 막기 위한 활동을 하고자 할 것입니다.
그런데, 실제 연체자 수 10명중[TP(3) + FN(7)] 연체로 예측한 건 3건[TP(3)] 밖에 안됩니다. 이것은 카드사가 원하는 결과가 아닙니다. 심지어 아래와 같은 경우도 생길 수 있습니다.
| Model B | Actually 연체 | Actually 납부 |
| Predicted 연체 | TP(0) | FP(0) |
| Predicted 납부 | FN(0) | TN(90) |
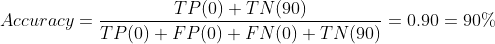
무조건 납부했다고 예측을 해버리면, 정확도 90%의 모델이 만들어집니다. 완전히 엉망인 결과인데도요..
몇 년 전 알파고가 등장하고 기업들이 너나할것없이 AI를 도입한다고 붐이 일어났습니다.
AI를 이용해서 이런 걸하겠다 저런 걸 하겠다. 프로젝트도 많았는데요. 당시에는 이런 평가지표에 대한 이해가 낮아서, 정확도는 높지만, 실제로 아무 쓸모도 없는 모델이 많이 만들어지곤 했습니다. 이런 걸 만들어 놓고 프로젝트가 성공했다고 상도 받고 하는 경우마저 종종 있었습니다.
요즘에는 마케팅이나 사업부서쪽도 데이터 분석에 대한 이해도가 전반적으로 높아져서, 이런 식의 사기(?)는 치기 어렵습니다. 그럼에도 불구하고, 회사에서 인턴 과제 같은 거 시켜보면 알고 그러는지 모르고 그러는지 이런 사기를 치려고 하는 경우가 있습니다ㅋㅋ
이렇게 정확도만으로는 모델을 평가하기 어렵기 때문에, 새로운 지표가 나옵니다.
Recall(재현율)
Recall은 실제로 긍정인 것 중 긍정으로 예측한 비율입니다. 실제 Positive인 것중 이 모델에서 찾아내어 재현한 비율입니다.
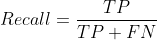
이 수식대로 앞서 만든 Model A의 Recall을 계산해보겠습니다.
| Model A | Actually 연체 | Actually 납부 |
| Predicted 연체 | TP(3) | FP(5) |
| Predicted 납부 | FN(7) | TN(85) |
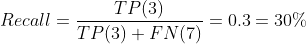
보시다시피 정확도는 높았지만, Recall은 0.3 밖에 안되는 모델이 만들어졌습니다. 보통 0.3이라고 하는데, 30%라고 써놓은 이유는 모델을 만들어서 Recall이 무엇인지 모르는 사람들에게 직관적으로 이해시키기 위함입니다. 0.3이라고 하면 이게 그냥 수치인지 비율인지 모르는 사람도 있거든요.
그럼 이렇게 Recall도 썼으니 이제 끝일까요? 이번에는 또 이런 모델을 만들 수 있습니다.
| Model C | Actually 연체 | Actually 납부 |
| Predicted 연체 | TP(10) | FP(90) |
| Predicted 납부 | FN(0) | TN(0) |
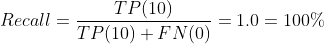
쓸모없는 모델을 만들었는데, Recall이 1.0 이네요. 그래서 이제 평가지표가 하나 더 나옵니다.
Precision(정밀도)
Precision은 긍정으로 예측한 것 중 실제 긍정인 것의 비율입니다. Positive로 예측한 것이 얼마나 정밀하게 실제 Positive를 찾아냈느냐.. 하는 지표입니다.
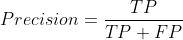
이 수식대로 Recall이 높았던 Model C의 Precision을 계산해보겠습니다.
| Model C | Actually 연체 | Actually 납부 |
| Predicted 연체 | TP(10) | FP(90) |
| Predicted 납부 | FN(0) | TN(0) |
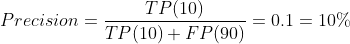
Recall만 극단적으로 올렸더니, Precision이 0.1밖에 되지 않습니다. 이 모델이 쓸모없다는 것을 보여줍니다.
F1-score
Recall과 Precision 은 둘다 올리는 것이 어렵습니다. Recall을 높이기 위해 긍정으로 예측하는 값을 늘리면 그중에 실제 긍정인 것의 비율은 줄어들기 때문에 Precision은 낮아지는 거죠. 그래서 두 개의 지표를 Trade-off관계에 있다고 합니다.
Recall만 높은 모델이나 Precision만 높은 모델을 만들지 않도록 두가지 지표를 모두 보아야 합니다.
그런데, 이렇게 두개를 보자니 불편해서 Recall과 Precision을 하나로 만들어 놓은 것이 F1-score입니다.
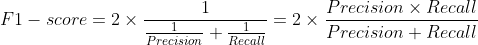
F1-score는 Recall과 Precision의 조화 평균을 의미하는 값인데,
단순한 평균이 아니라 값이 어느 한쪽에 치우치지 않을때 가장 높은 값을 가지게 됩니다.
기하학적으로는 아래 그림처럼 나타나게 됩니다. 작은 쪽으로 값이 치우쳐서 나오므로
큰 비중을 차지하는 지표의 bias가 줄어들게 됩니다.
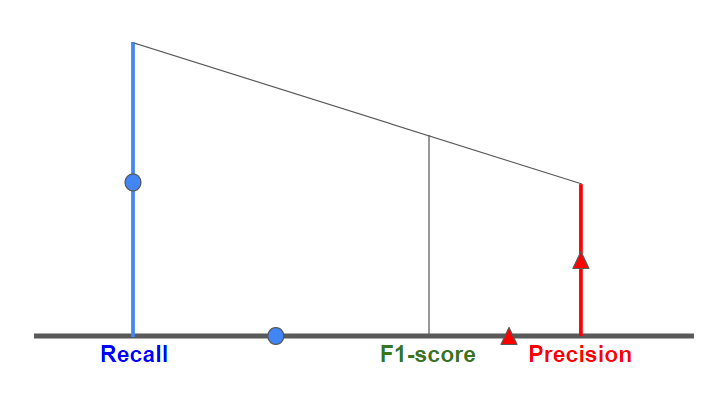
Model A, B, C의 F1-score 계산
앞서 살펴본 모델 A,B,C의 F1-score를 계산해 보면 아래와 같습니다.

특정 지표만 올렸던 모델에 비해서는 그래도 최초의 모델이 F1-score가 가장 좋게 나오는 것을 볼 수 있습니다.
마무리
이렇게 Confusion Matrix와 여기서 파생되는 Accuracy, Recall, Precision, F1-score에 대해 알아보았습니다.
예시로 든 것처럼 모델의 성능평가는 한 가지의 지표만 보면 결과를 왜곡할 수 있습니다. 다양한 지표로 평가하는 것이 중요합니다.
'데이터분석과 AI > 데이터분석과 AI 일반' 카테고리의 다른 글
| ChatGPT의 한계 - AGI(Artificial General Intelligence)와 ANI(Artificial Narrow Intelligence)의 차이 (0) | 2023.03.06 |
|---|---|
| ChatGPT 열풍!! 대체 뭐길래? 체험 후기 (2) | 2023.01.08 |
| [앱테크] 디지털 인형 눈알 붙이기(Labeling) 부업하기 - 캐시미션 (2) | 2022.09.22 |
| [앱테크]소소한 부업을 위한 설문조사 앱/사이트 추천 (0) | 2022.08.06 |
| 사내 AI해커톤(AI Play) 참여 후기 (1) | 2020.11.07 |




댓글